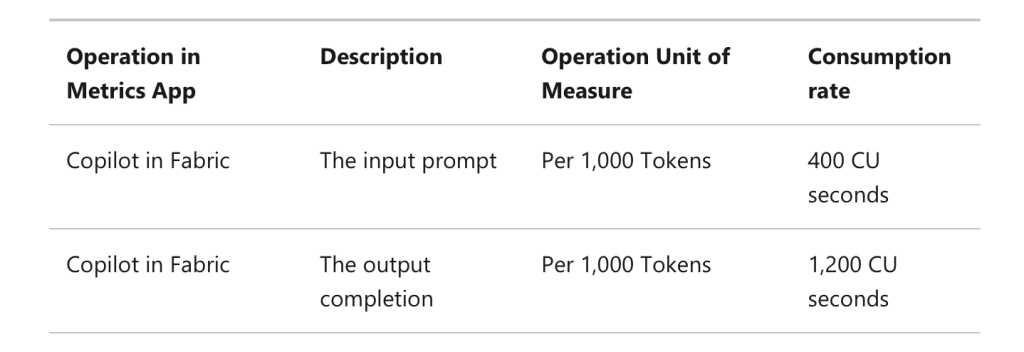
Some of the hardest challenges that I have seen people face while working on large projects are giving TCO and other cost-related estimates. Why? Plain and simple, many SaaS providers don’t make the enterprise plan cost available on their side. Those who do, make the pricing plans so complex that it would take a genius to figure out all the tiers and units used to measure the consumption. With LLMs now embedded in everything, there is one more such complexity in the picture now. If you are seeing tables like the below in pricing for these LLMs you might benefit from knowing what are tokens and what they mean in LLMs
As AI is progressing exponentially every day, we hear a lot about AGI and how it will replace humans at jobs. So it is natural to assume that the way information is processed in LLMs is similar to the way human beings process. But that is not the case. All LLMs take text as input and break that set of text into a logical grouping of numbers which has meaning for the model. For example, if I write a prompt like below, the co-pilot it will break the prompt into multiple tokens and then process it with the model to give an inference.

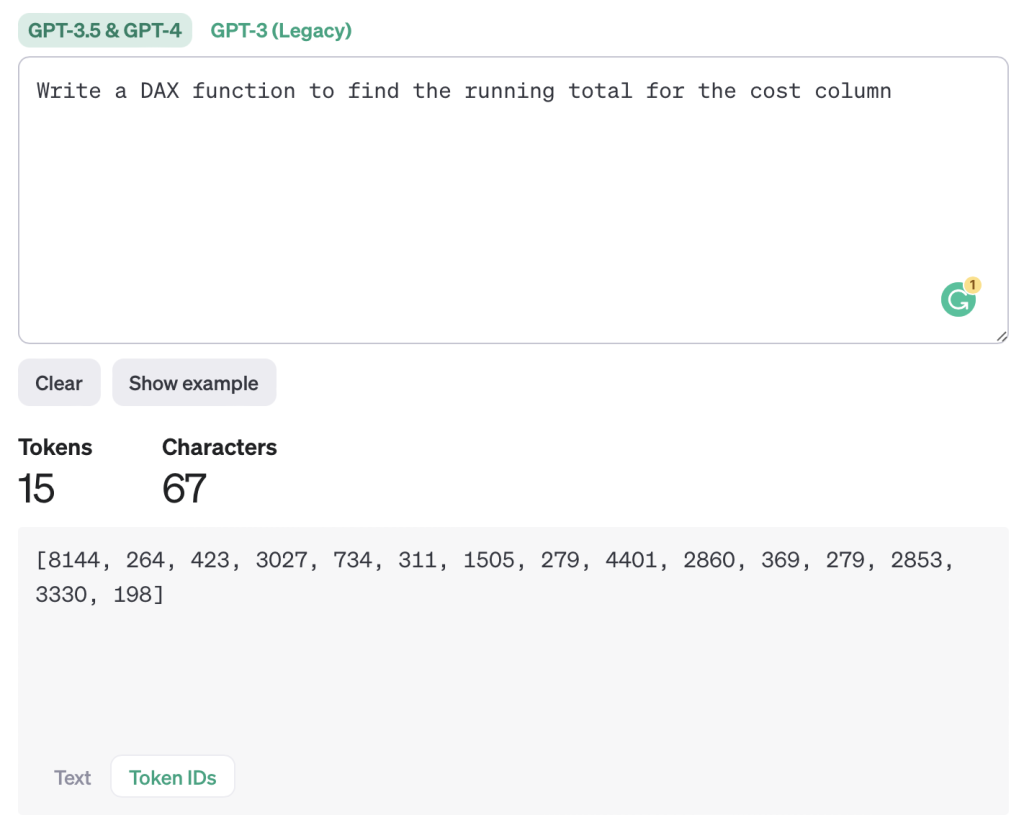
As you can see in the above screenshots, when we write a simple prompt to LLMs it will group those characters in a logical group and generate a set of token IDs. Those tokens are then processed by the foundational models and returned as an output. The output is also a set of tokens that is converted back to text for us.
There is no general mapping where one word in English is equal to one token. But from my experience, I think you can multiply the number for word count by 1.5 and it will give a rough idea of the number of tokens that will be consumed. The current model of GPT -4 has a token limit of 32,768 which would mean a word count of ~ 27,000. Not enough to write a book but good enough to write any assignment.
Fun fact, if you are using languages like Hindi or Chinese this calculation will not hold up and many times one character of the language will be translated into one token. That’s why I think we might see many localized LLMs as the way tokens are counted for these languages will mean higher costs.
Below is reading from OpenAI is sufficient to understand tokens:
https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-to-count-them